
A comparison between the two on-boarding processes
Let's imagine a scenario where we want to adopt a type checker...
Lately we've been noticing a lot of NaN's show up in our app. We search for the source and find the following code:
// math.js
function square(n) {
return n * n;
}
square("oops");We sigh to ourselves, and decide maybe it's finally time to add a type checker. We step back and take a look at our options: Flow or TypeScript.
Both of these tools have fairly simple file-by-file adoption:// @flow comment to the top of your file
.js extension to a .ts
extension
But let's compare what happens from there.
To adopt TypeScript, we'll first rename math.js to
math.ts:
// math.ts
function square(n) {
return n * n;
}
square("oops");Now we'll run typescript:
(no errors)There are no errors because TypeScript requires that we type annotate our function before it will check the type like this:
function square(n: number): number {
return n * n;
}
square("oops");But without those types, TypeScript will do one of two things depending on your configuration:
any. This any type will
opt you out of all type checking.
--noImplicitAny option, it will throw
an error for any unknown types, requiring you to add type annotations.
This means that the amount of code covered by TypeScript is tied to the types that you have written. Type coverage goes up linearly as you write types.
Before we go any further, I should explain what type coverage is.
If you look at the values and expressions in your code and asked the type checker "do you know what type this is?".
If the type checker knows the type, then that value or expression is covered. If the type checker does not know the type then it's not covered.
The percentage of code for which the type checker knows the type is the "type coverage" of your program.
You want your programs to have as much type coverage as possible because then it will be able to tell you when you've made mistakes in more places.
Without type coverage, a type checker is nothing.
// @flow
function square(n) {
return n * n;
}
square("oops");Then we'll run Flow and see the results:
function square(n) {
return n * n;
^ ^
Error (x2)
}
square("oops");
Error (x2)
string. The operand of an arithmetic operation must be a number.Immediately we have type errors that tell us something has gone wrong.
Flow only requires us to type the exports of a file and the external modules. Everything else can be inferred.
This makes type coverage go up much faster. With just a few types you can quickly get files with really high type coverage.
In my experience, I can get files covered to about 70–90% in just a few minutes.
Here's a super scientific graph of the difference:
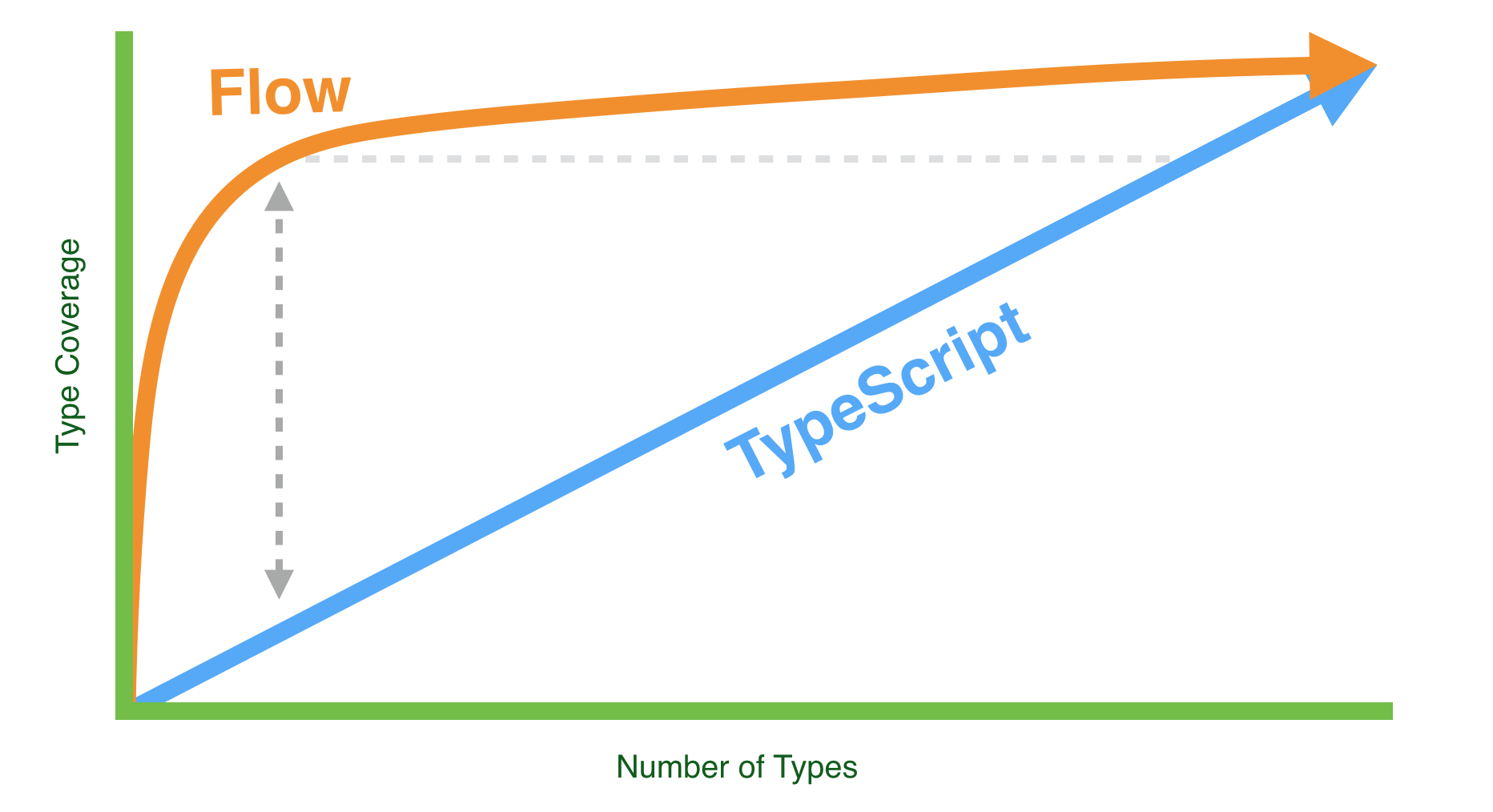
This isn't my personal opinion, you can go out and try this for yourselves and see the difference a few types makes.
To see the type coverage of a file in Flow you can run:
flow coverage path/to/file.js --colorYou can also use flow-coverage-report to help you out.
The reason these two tools have such different adoption behaviors comes down to the difference between their architectures.
TypeScript will walk through your program and build up a table of
known types. As it discovers values and expressions it assigns types to them
immediately. When TypeScript discovers an unknown type it must make a
decision immediately, which means either assigning it to any or
throwing an error.
Flow will build up a graph of all your values and expressions and their relationships to one another. It will then start to assign types to each value and expression. If it finds an unknown type it will make it an "open" type and come back to it later.
Once Flow has a full graph of your program it will start to connect all the dots, flowing types from one value to another. Open types take on the types of all the values that flow into them– the resulting type is called the inferred type.
You can watch this happening. Let's take a look at the type errors we got with Flow before:
function square(n) {
return n * n;
^ ^
Error (x2)
}
square("oops");
Error (x2)
string. The operand of an arithmetic operation must be a number.
Notice how error is pointing to the n * n rather than
square("oops"). Because we didn't write a type for n the
"oops" string flowed into it and Flow started checking n as if
it were a string.
Adding a type annotation we can see the error move:
function square(n: number) {
return n * n;
}
square("oops");
^ Error
Error: string.
This type is incompatible with the expected param type of number.This raises an important point: Just because Flow can infer types everywhere doesn't mean that you shouldn't add type annotate your code.
Both TypeScript and Flow have really good on-boarding processes. Going file-by-file is a great experience.
However, if you use Flow, you'll have much higher type coverage much faster and you'll be able to sleep soundly.
With Flow you'll be adding types to make errors nicer, not to uncover them.